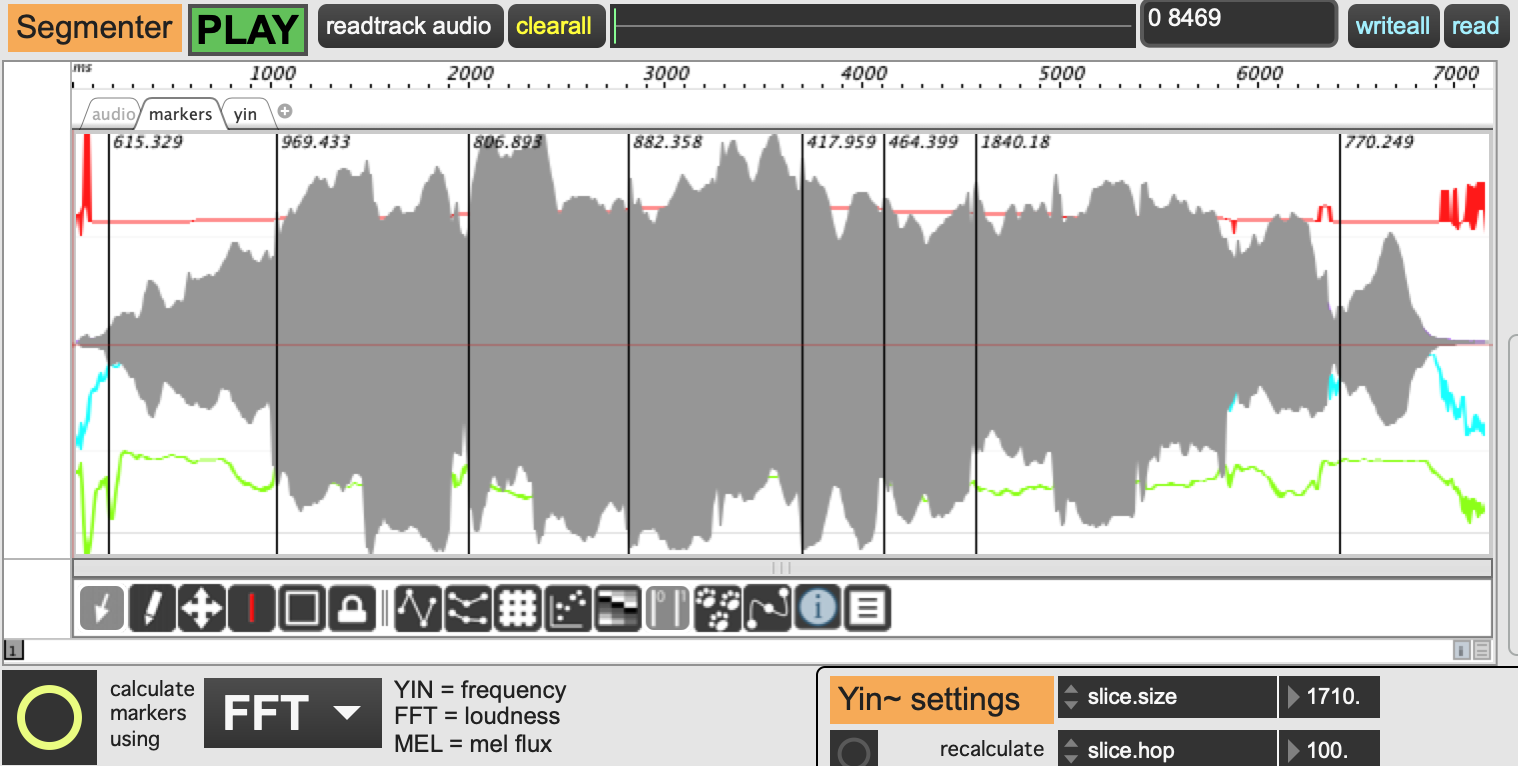
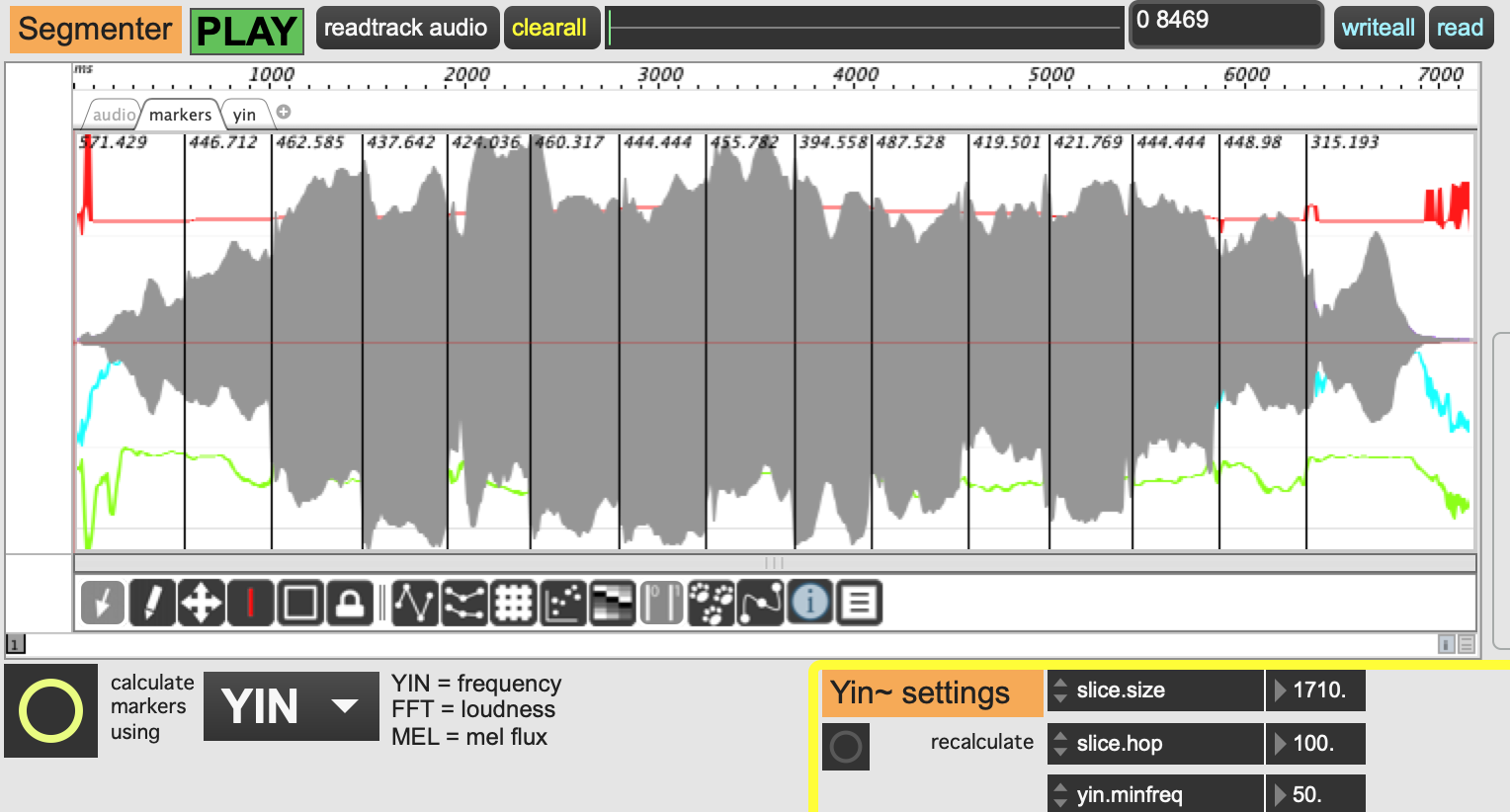
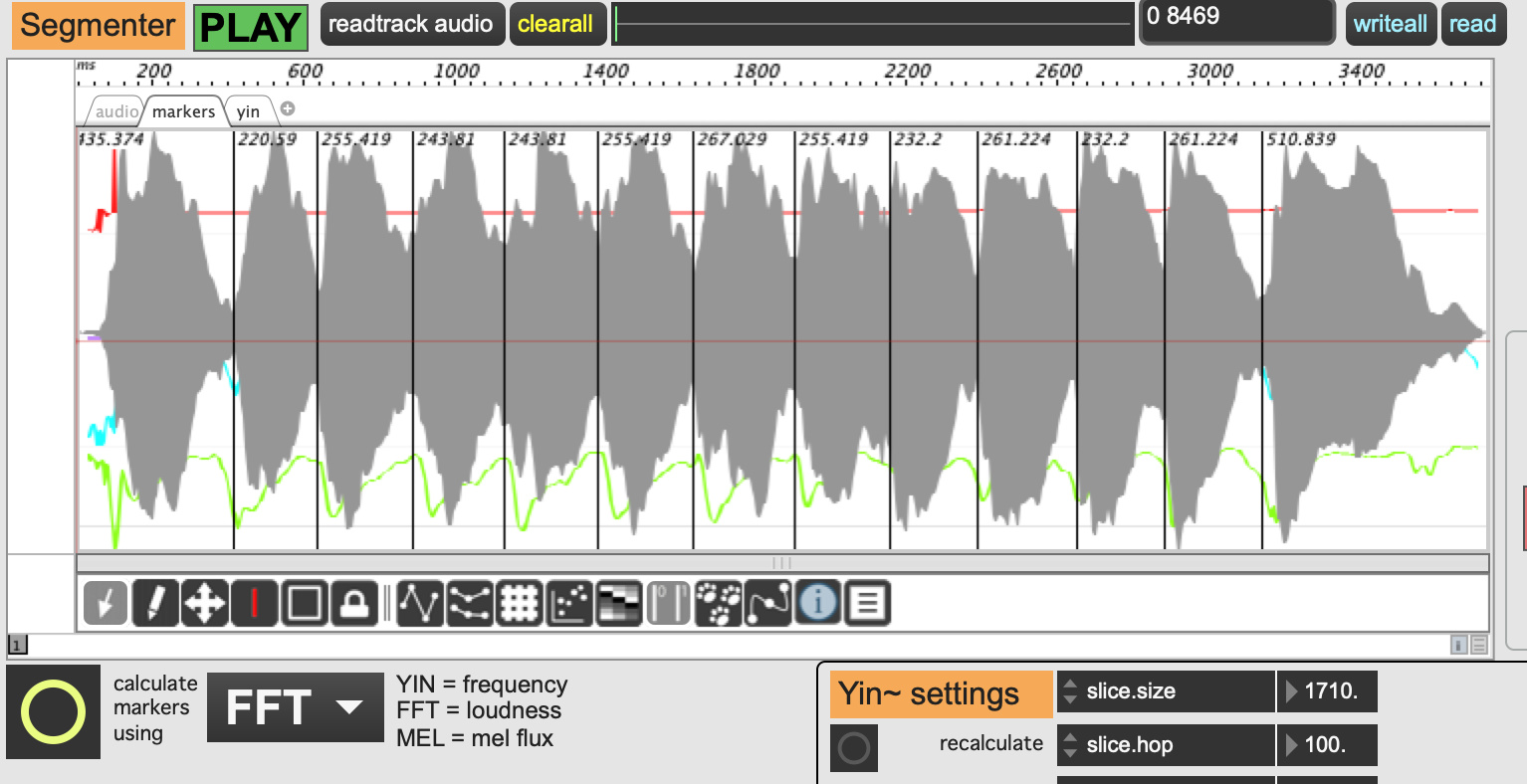
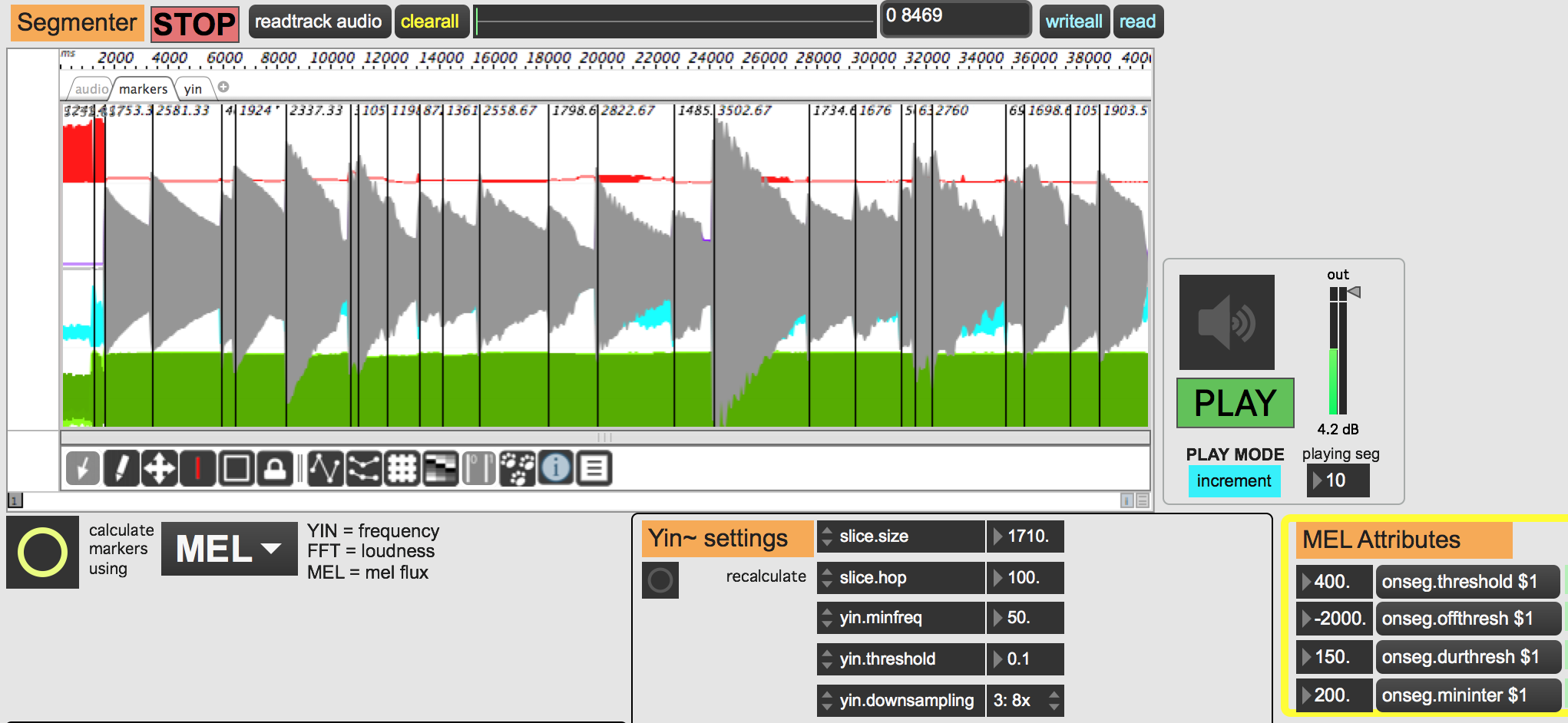
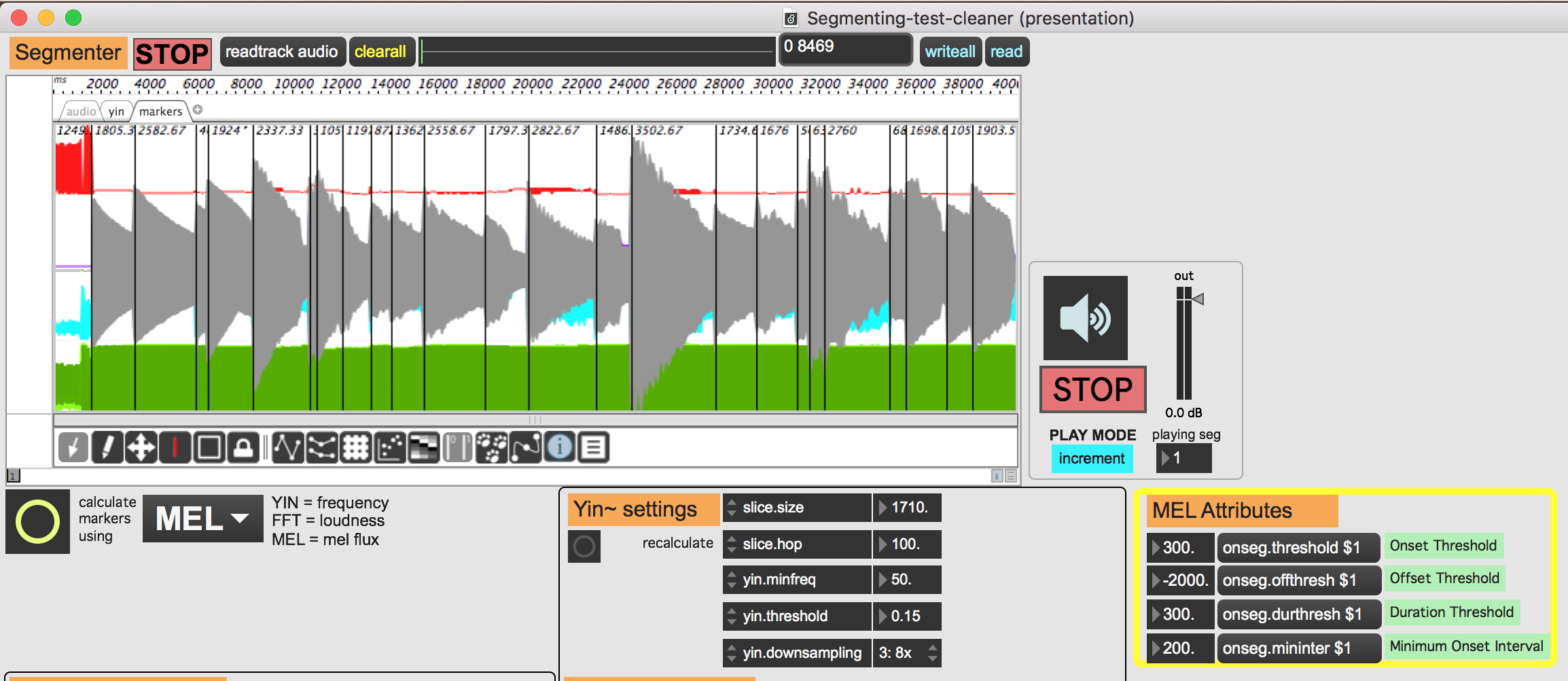
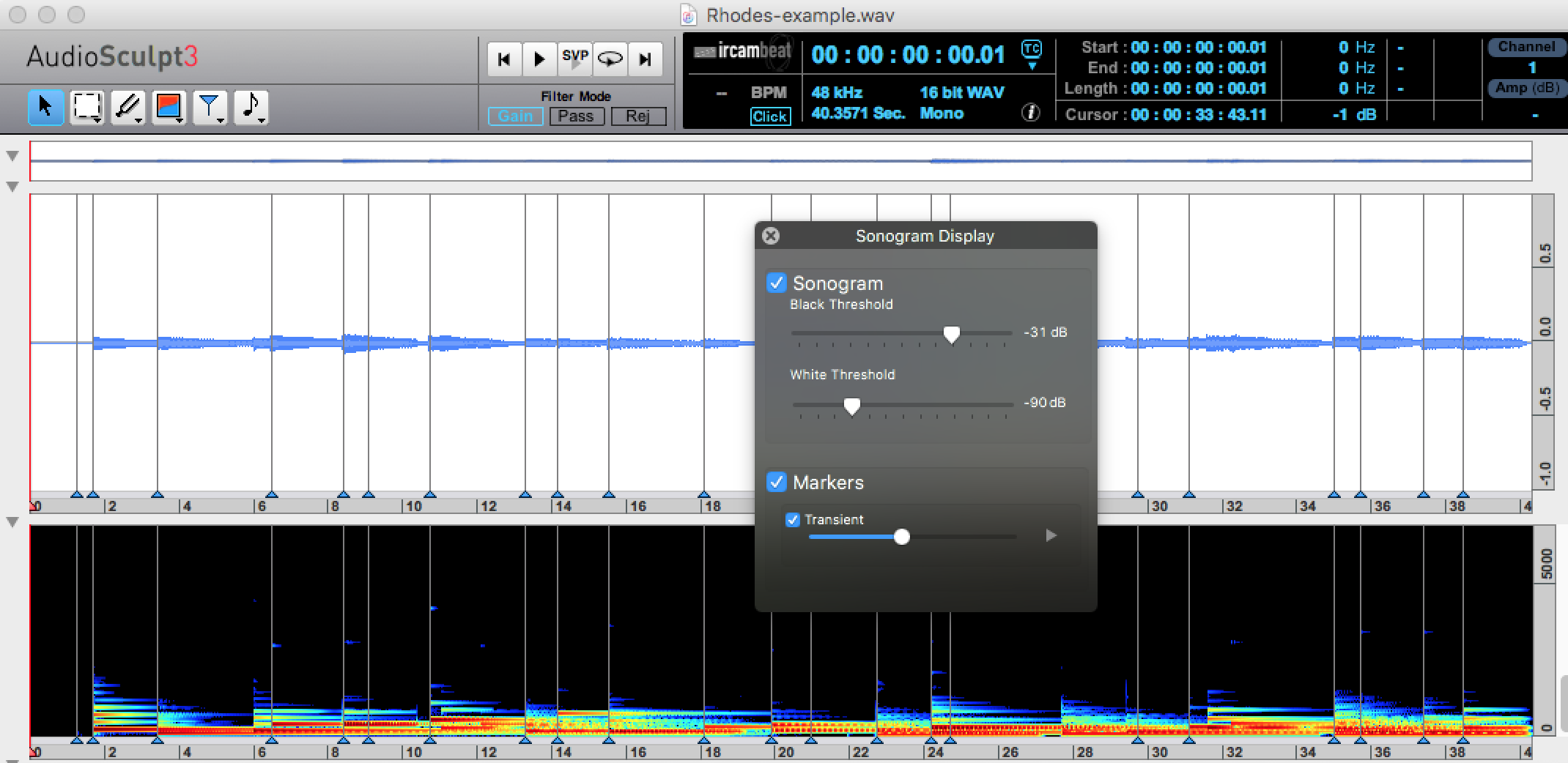
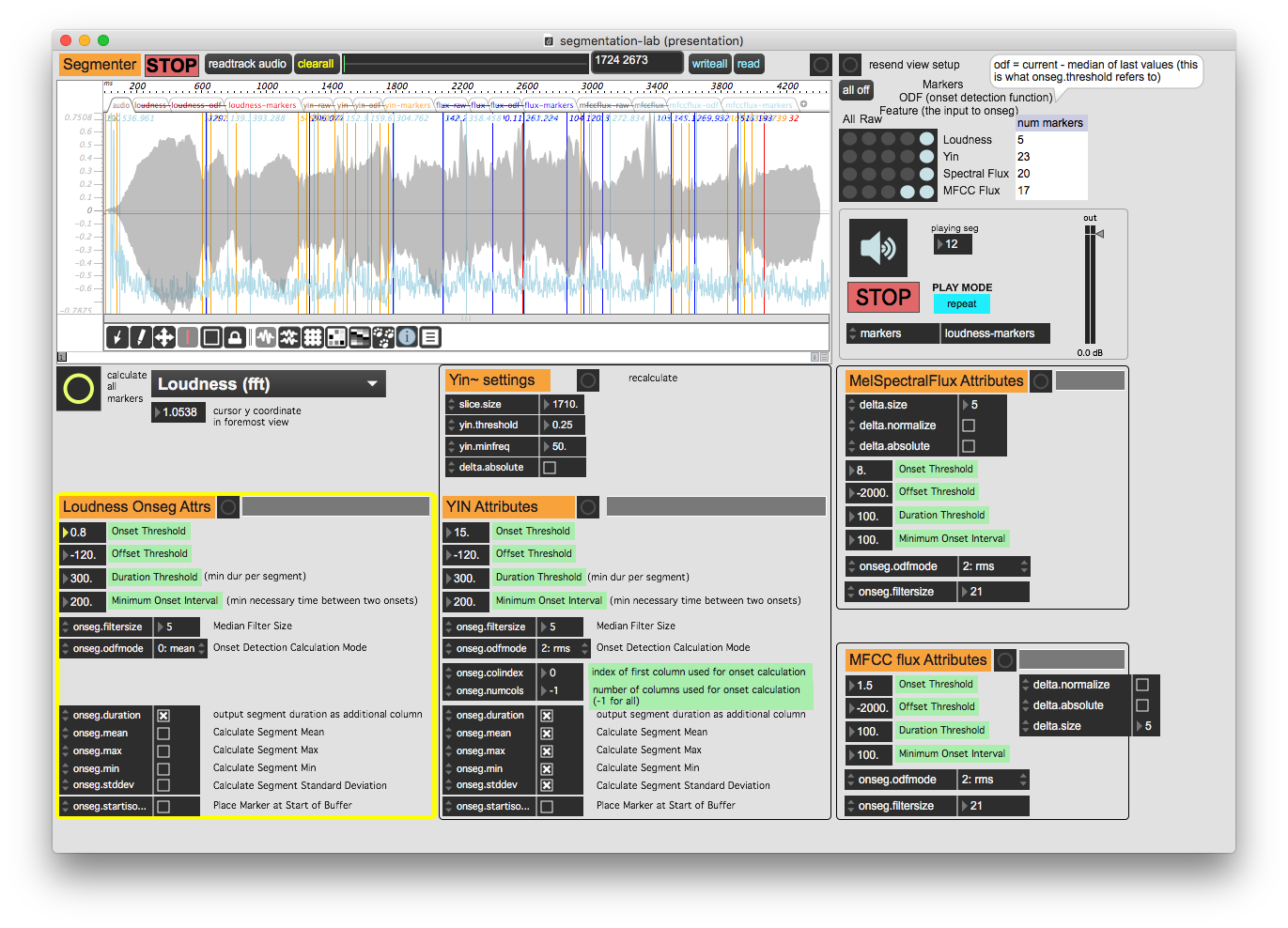
Here is a short flute arpeggio which is really difficult to segment.
I needed to lower the onseg.threshold down to 100, then I got most of the markers at the beginning of each note. Perhaps that is quite similar to the melodica.
But its really sensitive on the kind of input and the amplitude. I guess there are a few more tweaks available which will make the detection more adaptable to different source material.
Detection is definitely challenging with wind-based instruments with continuous changes between notes. I’d like to give Sequenza a try, but first I am just trying to get my head around basic tests like the flute arpeggio here.