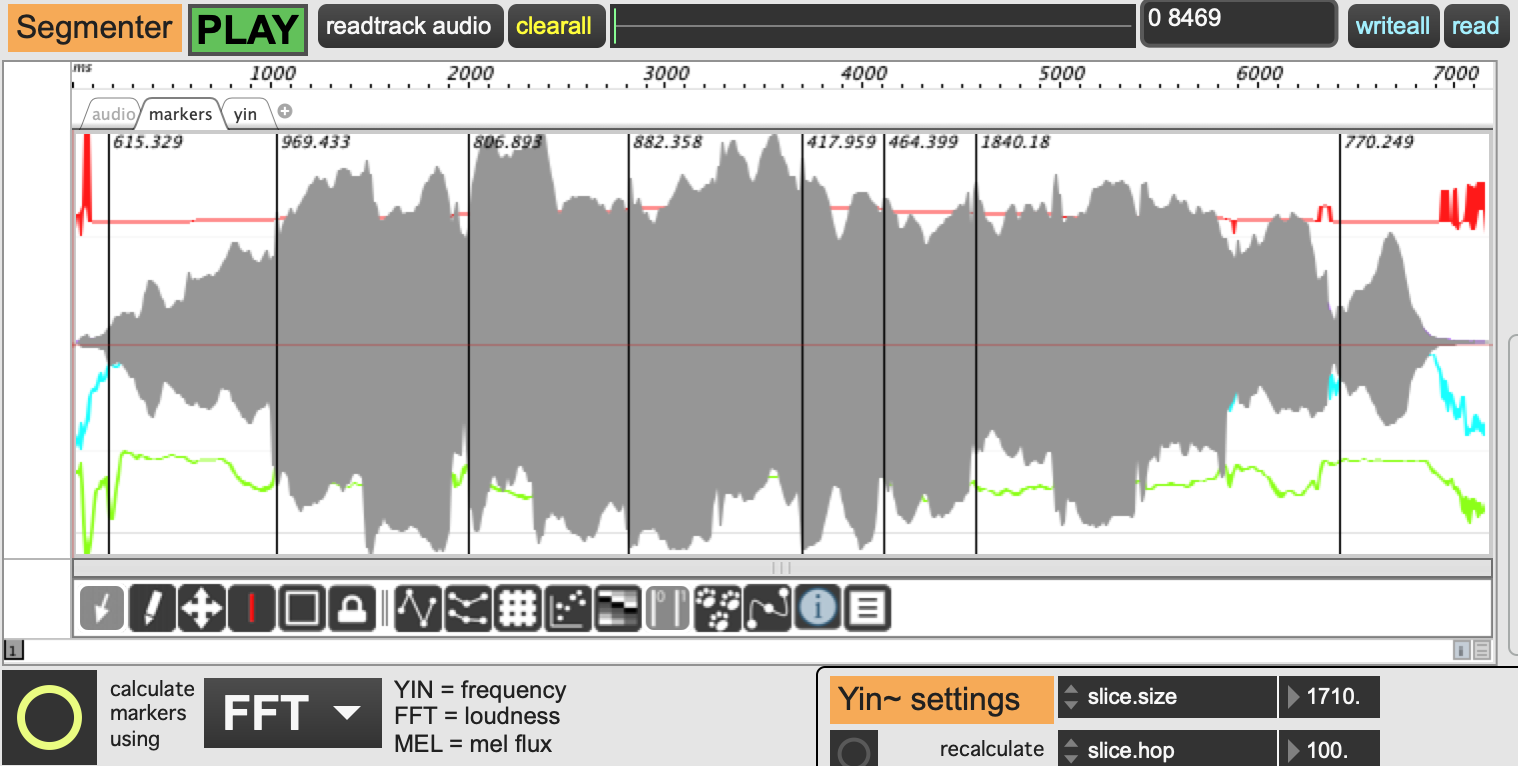
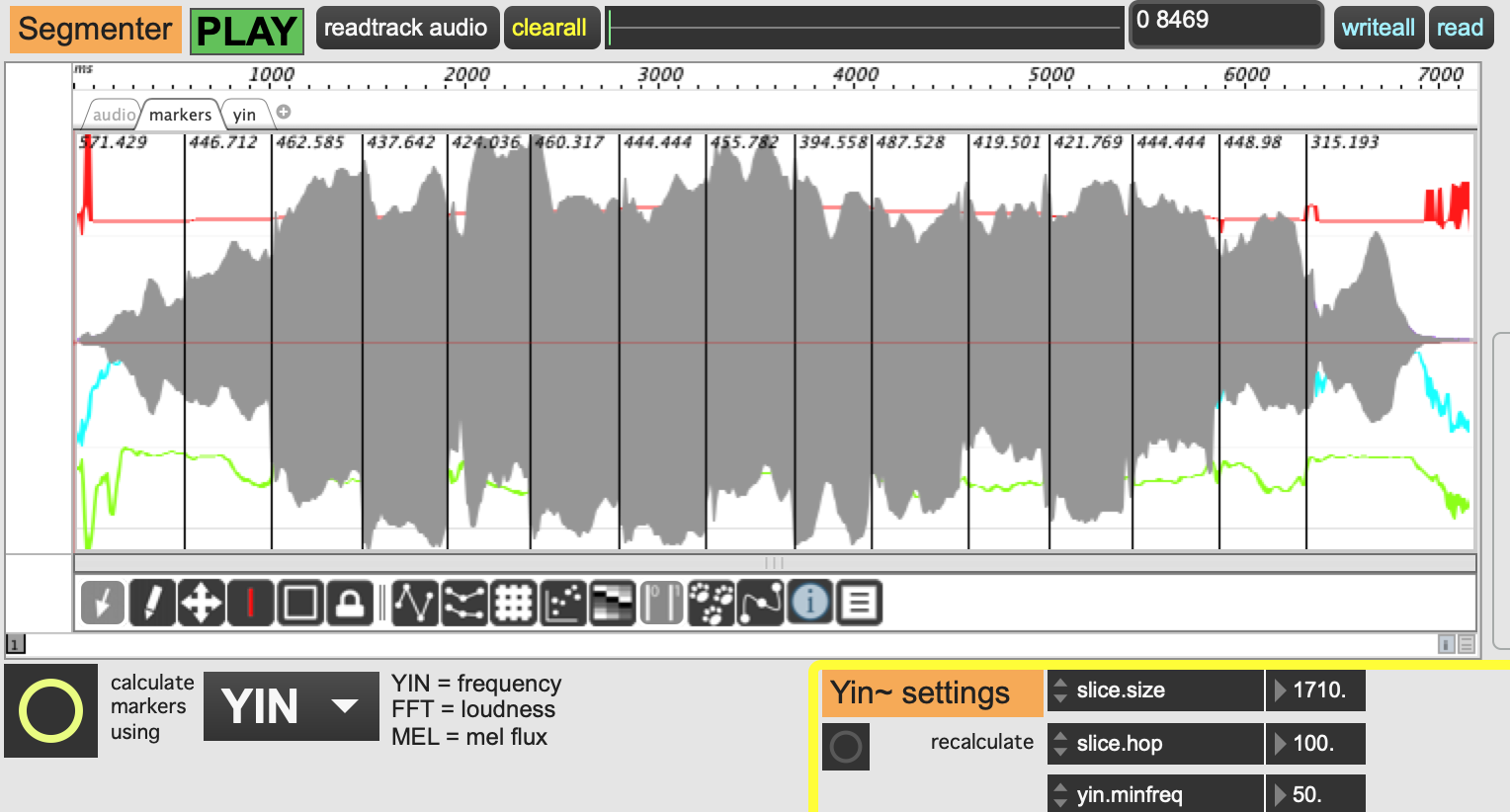
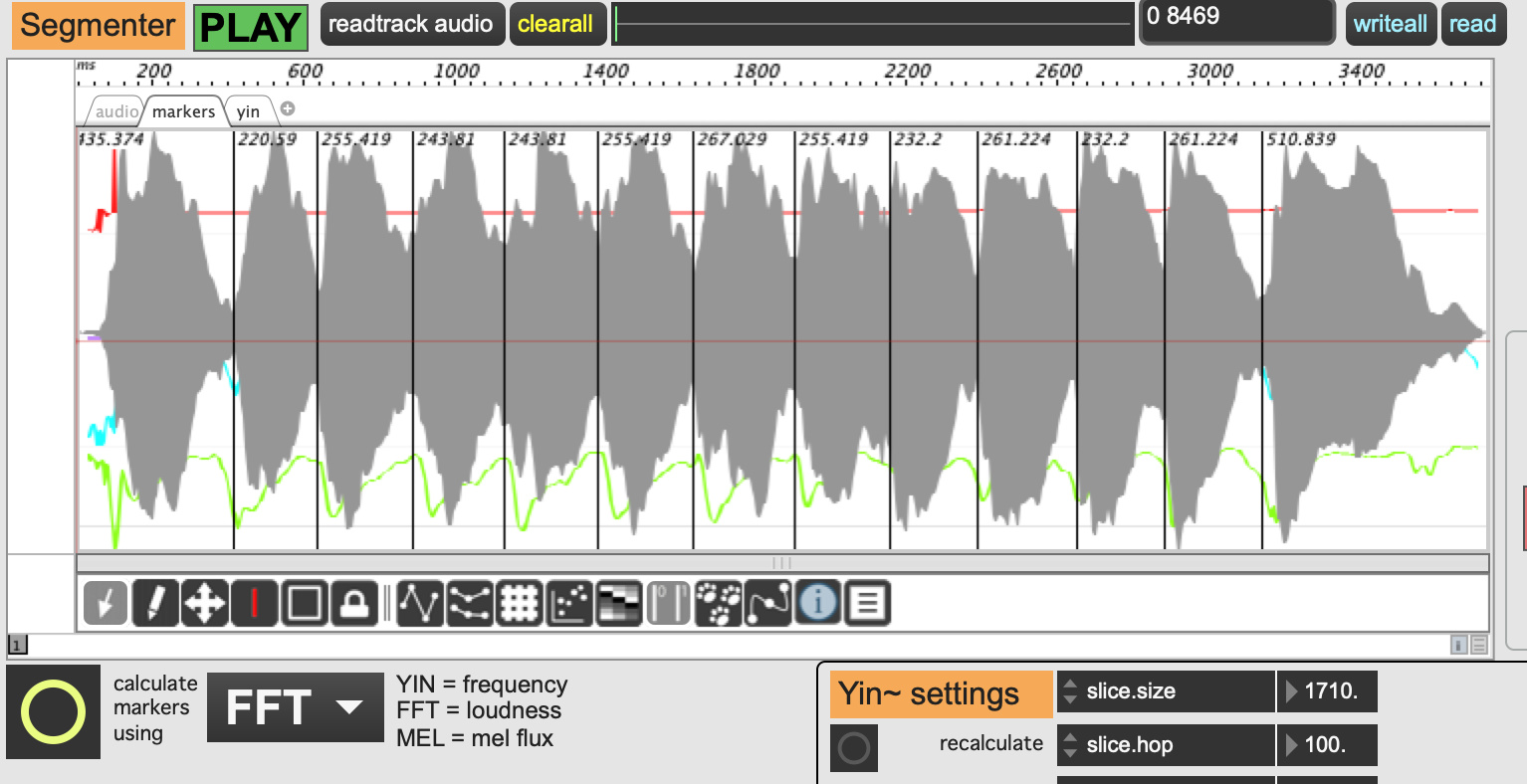
I am trying to find out if there is a way to create a PiPo chain that will enable me to detect onsets based on transitions in the distribution of mel frequencies. The help file provides the standard example of slice:fft:sum:scale:onseg which is basically a loudness based onset detection algorithm. I have also seen slice:yin:scale:onseg. However these algorithms are not optimized to detect transitions where the overall spectral energy remains quite even, but there is clearly a perceptible “edge”, such as in note transitions.
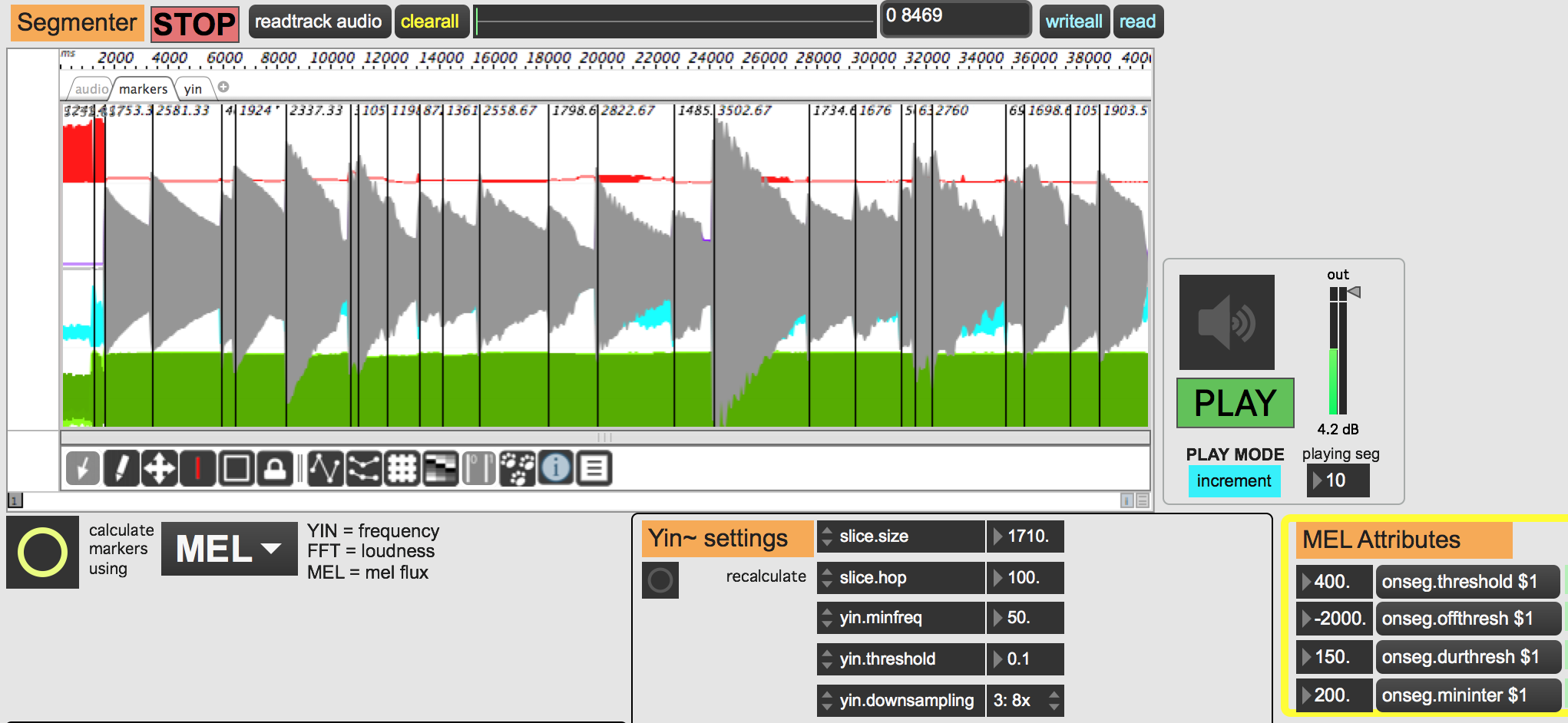
I tried mel:scale:onseg but there is clearly a qualifier missing here. I do not want to sum the mel values, I want the detector to look for sudden shifts in the mel band distribution (either direction).
Hope someone can point me in the right direction!