Hi Thibaut,
Thank you for the thorough reply. Does the spat5.hoa.binaural object requires speaker coordinates? Looking at the comparison patch from the help file, it seems that it only requires a norm and an HRTF folder reference. Is that the case? This implies there are no actual virtual speakers at all?
Thank you Thibaut. Does spat5.hoa.binaural~ uses virtual speakers? I am wondering about getting the speakers coordinates / the possible use of phantom speakers at 90° and -90° elevation, as this option is offered for the spat5.hoa.decoder~. Does it make sense to use it? Or does spat5.hoa.binaural~ provides the best layout possible, regardless we resort to the phantom speakers ?
Actually, to be more “square”, I should ask about the difference between the options offered in the spat5.hoa.decoder~ in general, such as the decoding technique and optimization possibilities. I assume these are not reproduced in the spat5.ambisonics.hoa~ object?
spat5.hoa.binaural~ uses the best possible layout of virtual speakers, and therefore the phantom option is not necessary.
Given the optimal virtual speaker layout, the object internally uses the sampling decoder method for decoding.
Other options such as /blocksize and /hrir/length refer to the convolution process, and they impact the cpu load.
I assume these are not reproduced in the spat5.ambisonics.hoa~ object?
Hi Thibaut,
Sorry, my mistake. I was talking about the spat5.hoa.decoder~ : method, type, energy compensation and so on.
I am afraid my understanding of the convolution parameters is still too limited to make the most of spat5.hoa.binaural~ , and since I’m using the project for clients who need a robust solution, I’ll stick to approach #2.
I have another question regarding the hrtfs though. I had been using raw Ircam hrts in a former project, and found them quite satisfactory in 2D. I was less convinced for the 3D (I had tested them all, and picked the individual that worked best for me).
Have you compared them with the Kemar, or have you read anything about possible comparisons? Since the patch will be used by quite a lot of different people, I wonder which bank is more efficient.
If I should switch to another bank, are the Ircam hrtfs on the SOFA format? Is it OK to load a folder that contains a set of Ircam individualized Hrtfs?
Thank you!
Coralie
Well, I strongly recommend not to use “raw” HRTFs.
As the name suggests, these are raw data from the measurement, without any post-processing to “clean-up” the acoustical measurement.
This is essentially useful for scientific analysis; but not really for “listening” purpose.
You should rather use the “Compensated” HRTFs, which have been post-processed, cleaned-up, equalized, diffuse-field equalized, etc.
(see spat5.sofa.loader)
I was less convinced for the 3D
That’s not entirely surprising : perception of height strongly depends on individual cues.
So non-individualized HRTFs usually work better in the horizontal plane.
Have you compared them with the Kemar, or have you read anything about possible comparisons?
No, we havent compared. It is likely that some people have made comparisons; but I dont have any reference to recommend.
I wonder which bank is more efficient
Have a look here :
are the Ircam hrtfs on the SOFA format?
Yes. (see spat5.sofa.loader)
Is it OK to load a folder that contains a set of Ircam individualized Hrtfs?
Hi @tcarpent and @coraliediatkine.
I have a similar workflow as @coraliediatkine and I’m struggling trying to wrap my head around the issue. I have a B-format 4 chan ambient recording, plus some additional sounds that I want to render as sound sources in a binaural scene.
So it makes more sense to encode the b-format file to a higher order and the decoden it with the hoa.binaural~ object, and the use another encoder for the sound other sound sources? Basically one will have two parallel encoders, one for the B to HOA and other for the sound sources to HOA. And the both outputs of the encoders get summed in the input of the hoa.binaural object. And that is it?
Does this make sense? Or shoudl I add the patch? I tried it already and to my ears sounds just fine. It blends well and I don’t hear anything particularly glitchy.
Thanks!
Why would you “encode the b-format file to a higher order” ?
Not sure what you mean by that, but it seems like just wasting (a bit of) cpu, but that wouldn’t improve the rendering/spatial resolution.
On one hand : encode your additional sounds into N-order HOA (say ACN/SN3D).
On the other hand : make sure your b-format stream is “converted” to the same Ambisonic format (ACN / SN3D), thanks to spat5.hoa.sorting~ and spat5.hoa.converter~.
(also apply 90° rotation if needed – have a look at spat5.tuto-bformat.maxpat)
Then sum up the two streams.
HOA is hierarchical, so it is legit to sum several HOA streams even if their orders differ.
i.e. you can sum a 1st order stream and a N-order stream.
Finally, decode this N-order stream to binaural. (using e.g. spat5.hoa.binaural~)
So, yes your workflow makes sense.
You can send a (strip-down) patch if you really have a doubt.
Thanks for your response Thibaut.
Yes, my idea was to “encode” the B Format stream to an N-order HOA so it will match the order of the additional sounds.
But in that also means that I can encode my additional sounds in First Order Ambisonics, to save CPU right? Does this affect the precision of the localization? Or is it less noticeable because it’s going to the hoa.binaural anyways?
Thanks,
Nico
For your additional sounds, you probably want the best (spatial) precision, so you’d rather encode them in higher order. (although this will obviously increase the cpu load)
It should be noticeable, because the HRTFs you’ll use in spat5.hoa.binaural~ are able to provide very high orders.
You will likely notice a difference between 1st and say 4th order encoding. Due to perceptual limits, it is however likely that the differences between 4th and 5th (for example) are much more subtle.
So, you need to make experiments and adjust the encoding order to your needs/taste.
Hi Thibaut,
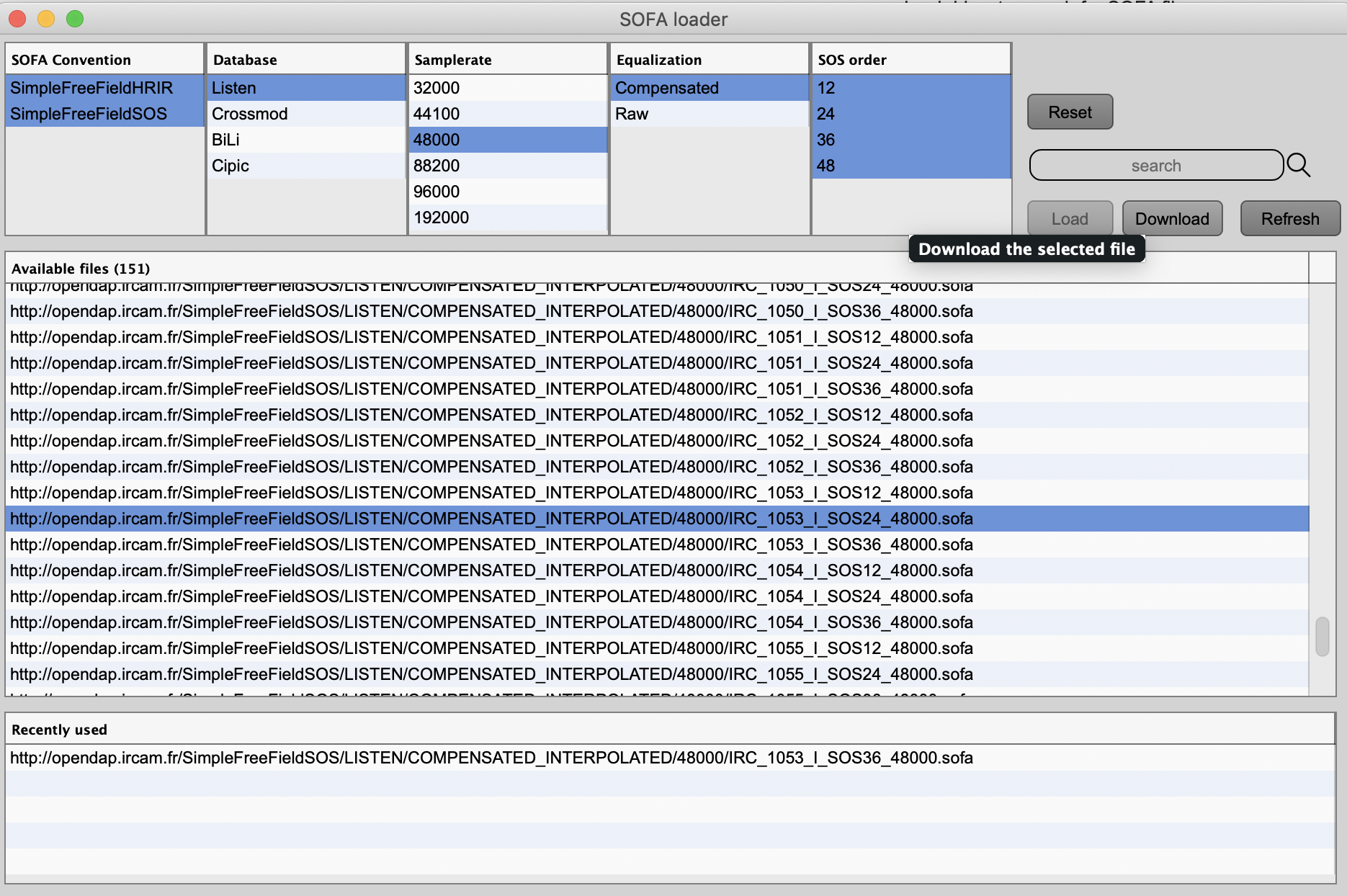
Sorry, I hadn’t understood the use of the spat5.sofa.loader. It’s a bit clearer to me now. So my question about loading one specific set of Hrtfs didn’t make sense at all.
If I understand, one has to filter the type of Hrtfs that they want to use, download it in Ircam/sofa directory, and then load it through a dialogue window for instance.
I am not certain I understand the difference between the SOS and HRIR data type. So far, I knew about the Listen and the Bili projects, but I had no idea about the SOS data type and its meaning. I have looked at the wiki about the SOFA convention, but I’m stuck when it comes to understanding the in and outs of that denomination. I don’t want to waste your time, so do you think this is important, and could you just give me a few directions to make a choice?
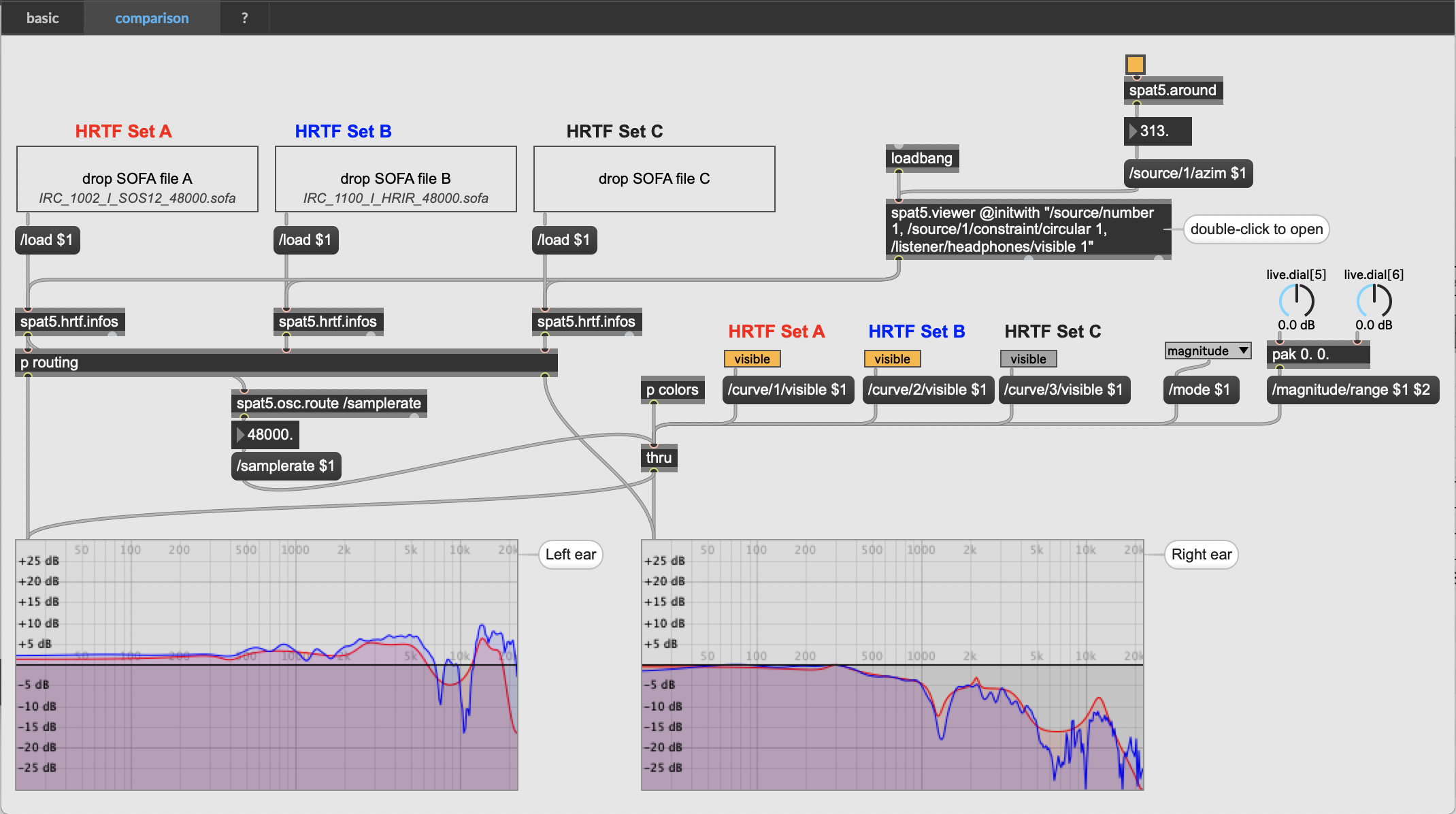
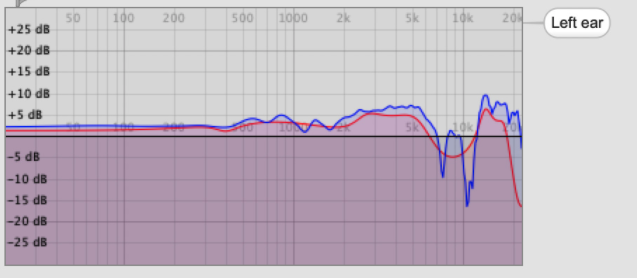
Edit: I have used the help patch to compare SOS and non SOS files, and SOS12, SOS24, SOS36. I have the feeling that SOS format allows maybe a more precise localization (the curves look less smooth), and that this is also increased with the SOS order. But I may be wrong. I’d like to make sure this makes sense from an aural standpoint.
Thanks
Coralie
Yes, spat5.sofa.loader gives you access to all HRTFs files on our servers.
You can download files, and later use them in your patch.
SOS stands for “second-order-sections”.
This means these are IIR filters. While HRIR are FIR filters.
SOS files are approximated versions of the original HRIR data.
The image you posted illustrates this approximation (on the frequency spectrum).
The red curve (SOS) is an approximation of the blue one (HRIR). (assuming you load the files corresponding to the same individual)
SOS rendering is A LOT less expensive than HRIR rendering.
SOS12 means 12th order IIR filter. It’s a rough approximation. But extremely cheap for CPU load.
SOS24 means 24th order IIR filter. Provides a more accurate approximation than SOS12. That’s my recommandation. Best tradeoff between quality and CPU load.
SOS36 means 36th order IIR filter. Usually, this only provides a marginal quality improvement compared to SOS24.
As you can see, SOS filters are usually a lot smoother than HRIR. This might also be a benefit for non-individualized listening. (SOS smoothes out strong peaks or notches that might be very specific to the measured individual)
In most situations, my recommandation is to use SOS24 files.
Hi Jérôme,
It’s just a screenshot of the “comparison” tab of the spat5.sofa.loader help patch. I used the automated azimuth panning in the patch, and loaded different hrtfs files.
Regards
Coralie