
Is there a way to make it so when you load a folder of sounds into MuBu, it automatically gets put into one buffer instead of each sound being in a different one? Thanks!
Hi,
just call readfolder without defining @name attribute. Each sound file will be loaded into a different track, but in the same buffer.
Best
1 Like
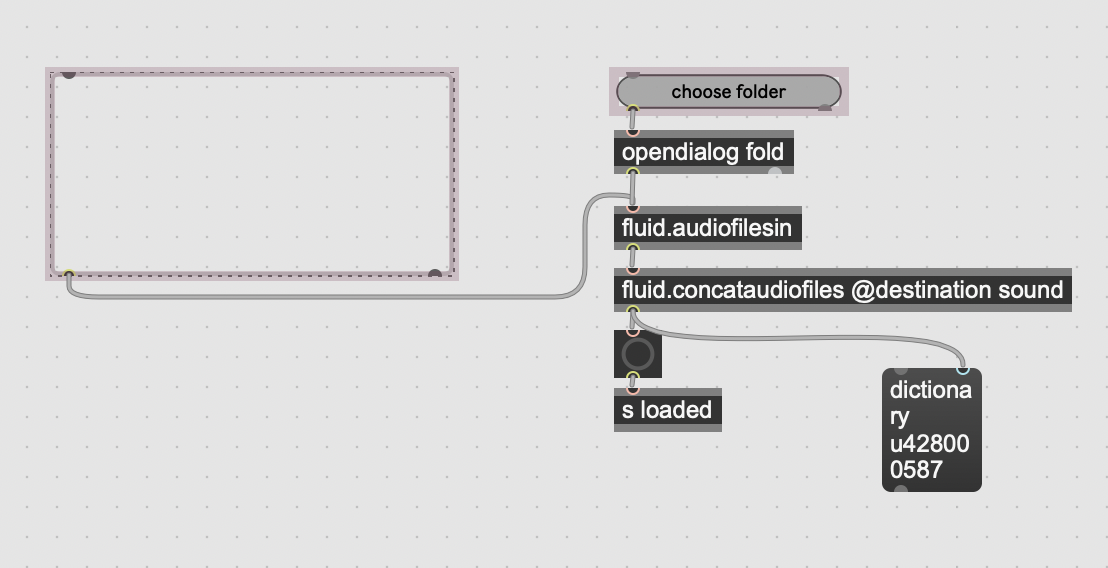
Hi Blair and Seraphim, thanks for this use case!
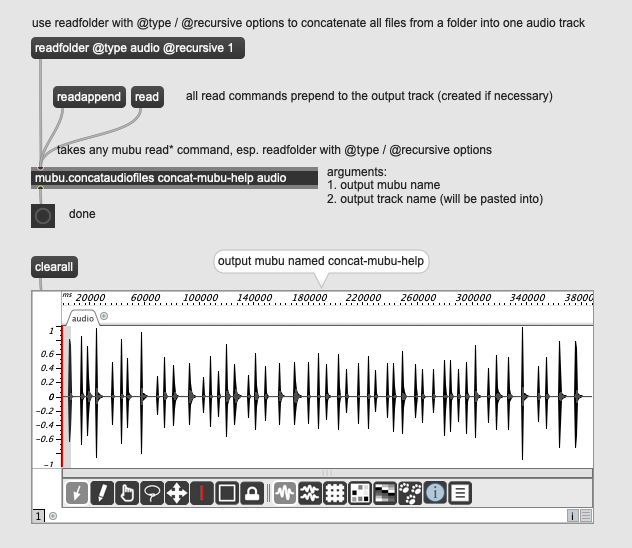
This is easy using track copy/paste and a temporary mubu. Here’s a little abstraction that does it for you. However, I think this could be a future option for the readfolder message.
mubu.concataudiofiles.maxpat (14.1 KB)
mubu.concataudiofiles.maxhelp (8 KB)
1 Like
Hey schwarz, using this approach, is it possible to have a mubu.process run
[mubu.process corpus audio descr:chop @name descr @process 0 @progressoutput input @timetagged 1 @chop.size 45 @chop.mean 1]
on all tracks within the buffer?
Hi,
- in my approach above, there is only one buffer and one audio track, so
mubu.processwill work fine. However, the chop in your pipo chain will sometimes combine the end of a sound file with the (concatenated) beginning of the next one into one segment. - With
readfolderwithout@namethere will be many audio tracks in one buffer, which doesn’t play well withmubu.processand does not make sense for a corpus. - The best approach for loading and analysing a whole corpus is
readfolder @name audio, which creates one buffer per sound file, each with one audio track, and this is handled perfectly well bymubu.process, which adds a segment+descriptor track for each buffer.
Best, Diemo
1 Like