Bonjour,
Non je ne fais pas référence à Python, ni à aucun langage informatique car je n’en maitrise aucun, mais simplement au concept mathématique. J’appelle ‘vecteur’ une note dans un chord-seq car c’est un objet qui comporte plusieurs variables, que je peux appeler ‘coordonnée’ (midic, onset, dur, vel etc.).
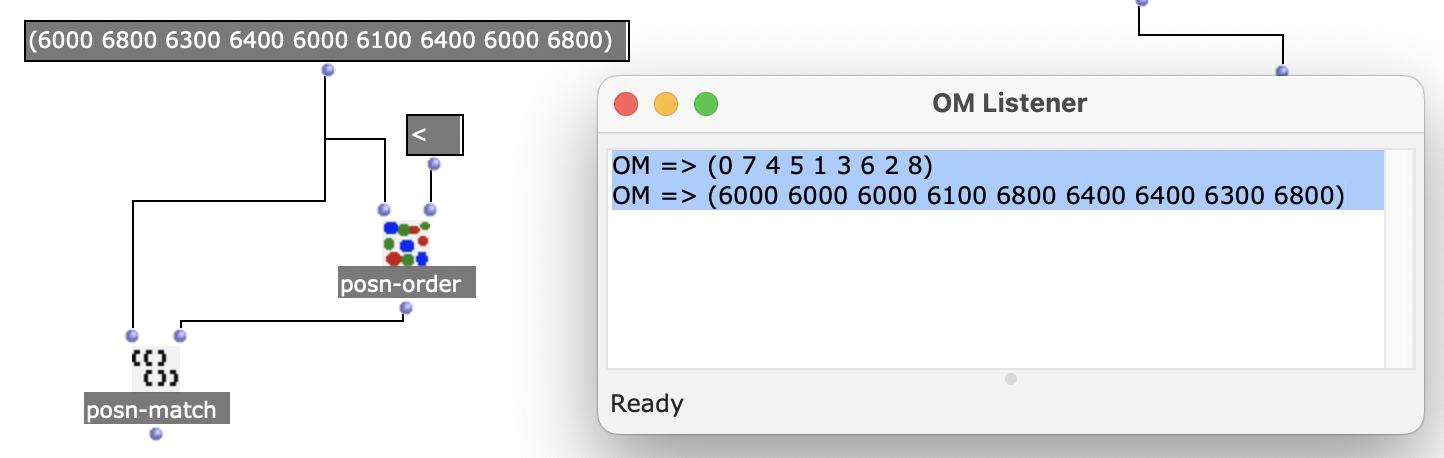
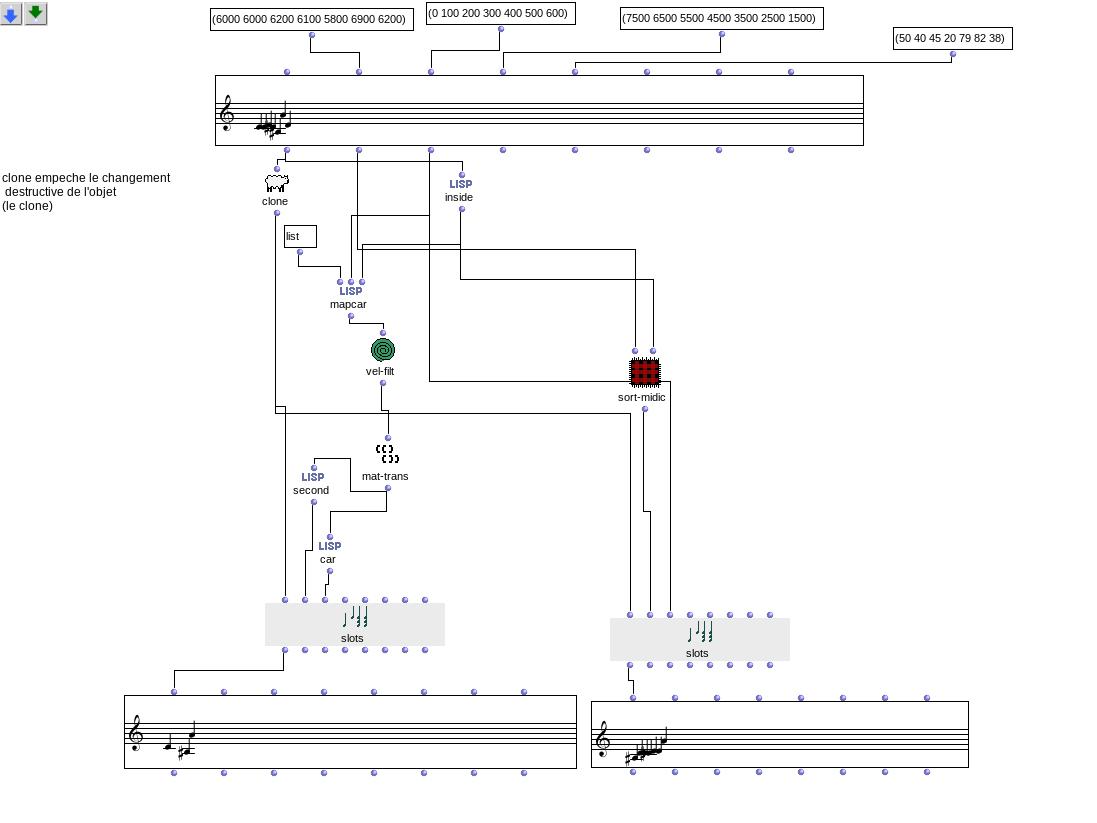
Le problème est lorsque l’on manipule l’une de ces coordonnées en sortie d’un chord-seq, par exemple la liste des midic, on n’intervient pas en même temps sur les autres coordonnées associées. Si je supprime une note dans lmidic, les autres variables associées (onset, dur etc.) ne sont pas supprimées.
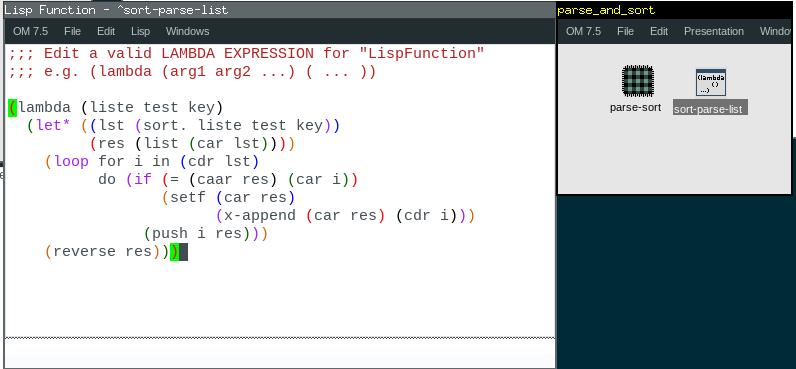
Dans un cas simple, par exemple, la gamme de Do à 60 à la noire dans un chord-seq A, si je veux supprimer la 5te puis afficher la nouvelle gamme dans un chord-seq B, je dois prendre chaque liste lmidic, lonset etc. et supprimer le 4ème élément de chacune d’elle, puis enfin rentrer les nouvelles listes dans les slot correspondants du chord-seq B. C’est la façon simple en manipulant les indices, mais cela suppose de les connaître.
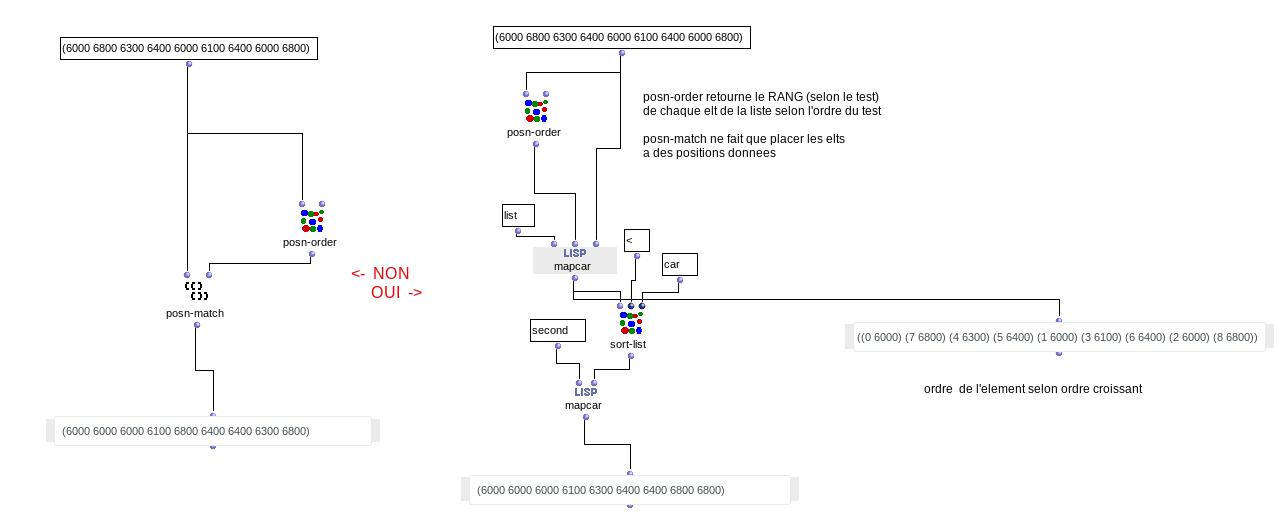
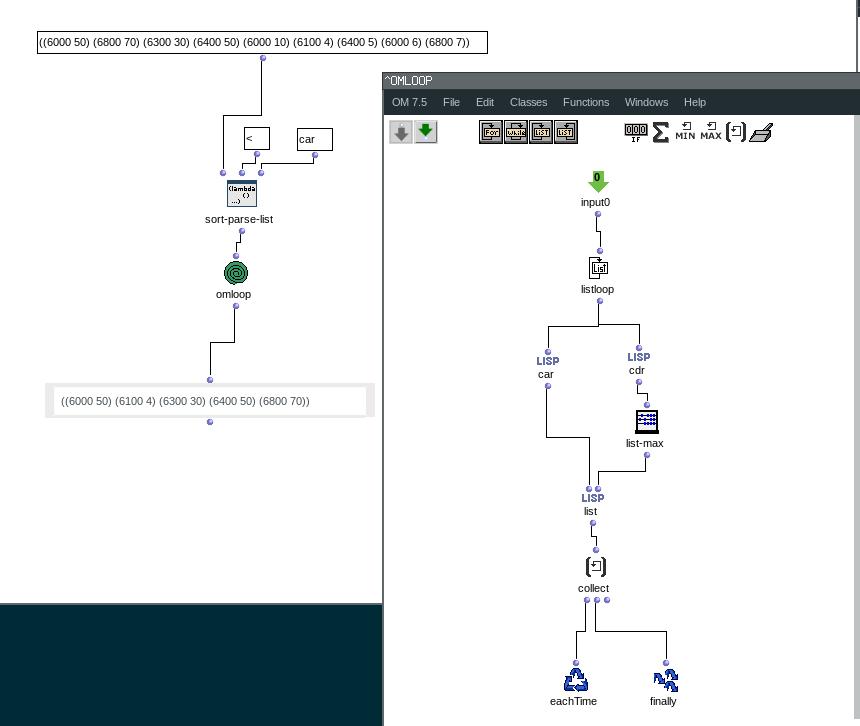
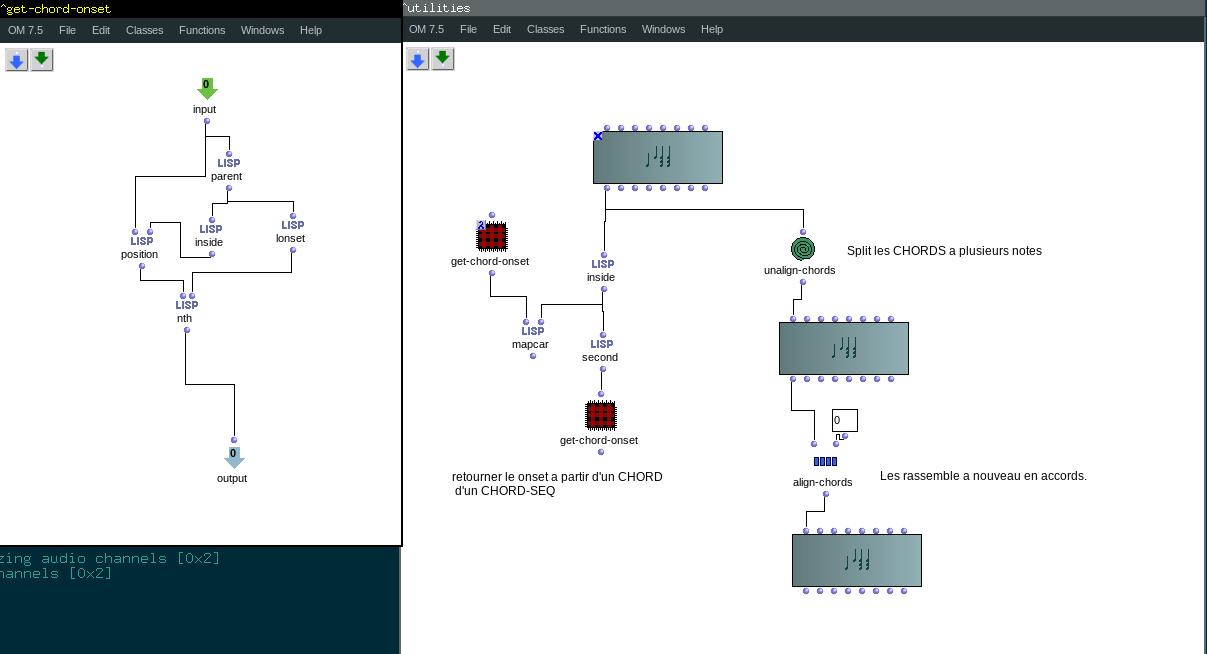
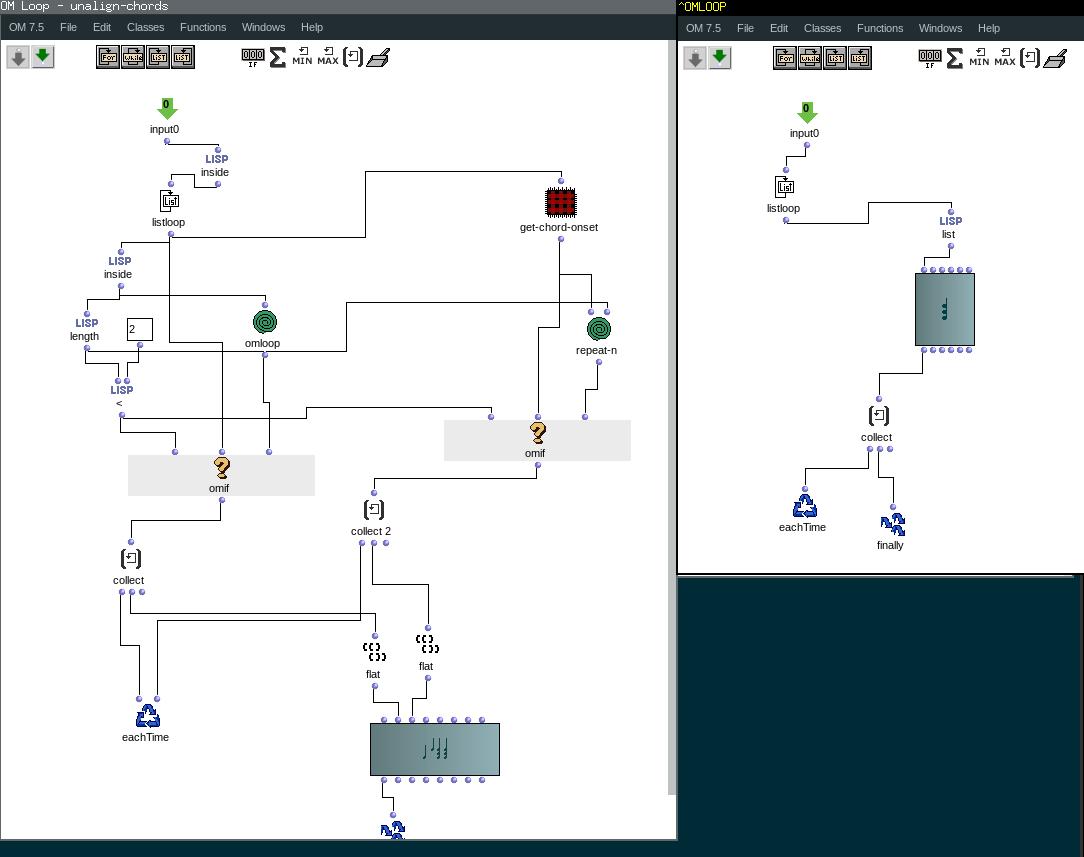
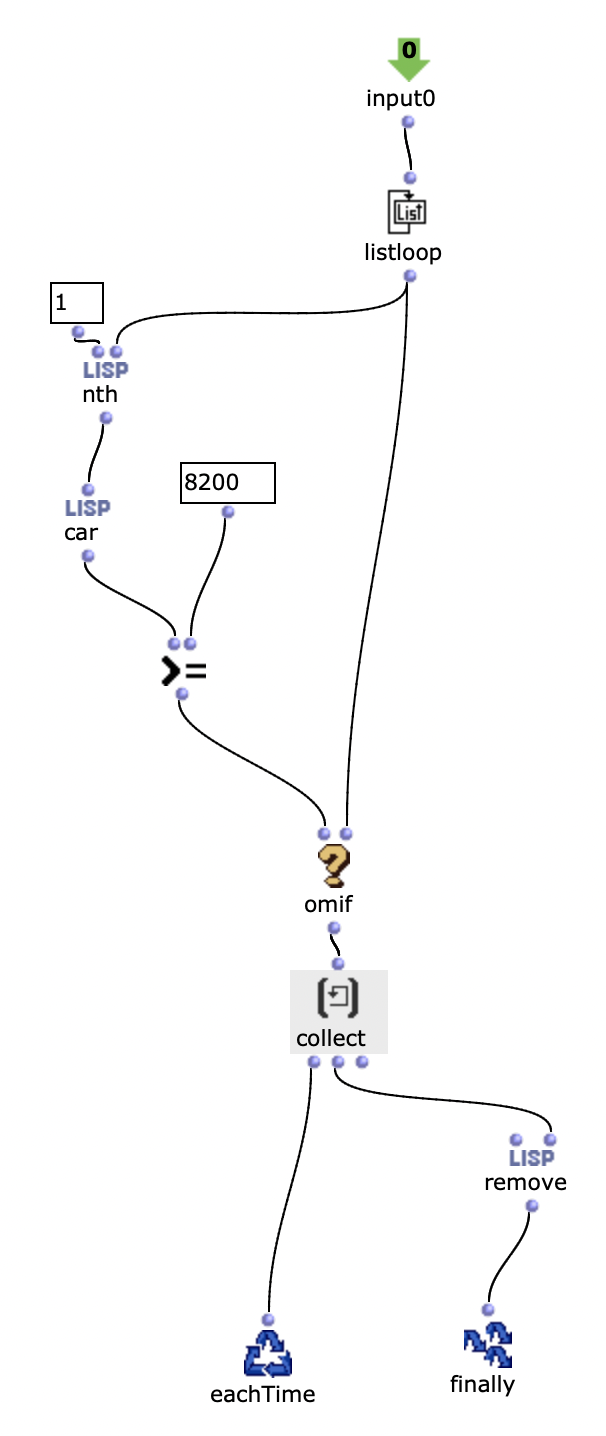
Mais je me demandais s’il n’était pas possible de manipuler plus globalement ces vecteurs, qui sont les évènements sonores d’un chord-seq, en manipulant les tableaux qui les représente : chaque colonne sont les coordonnées (note, dur, vel etc.) et chaque ligne un vecteur (numéro de la ligne = indice dans toutes les listes).
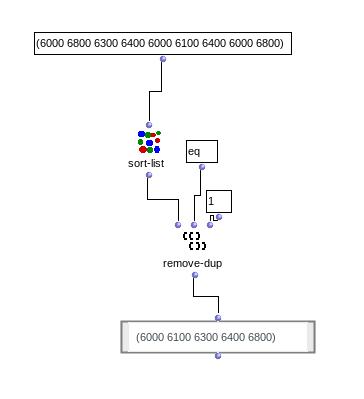
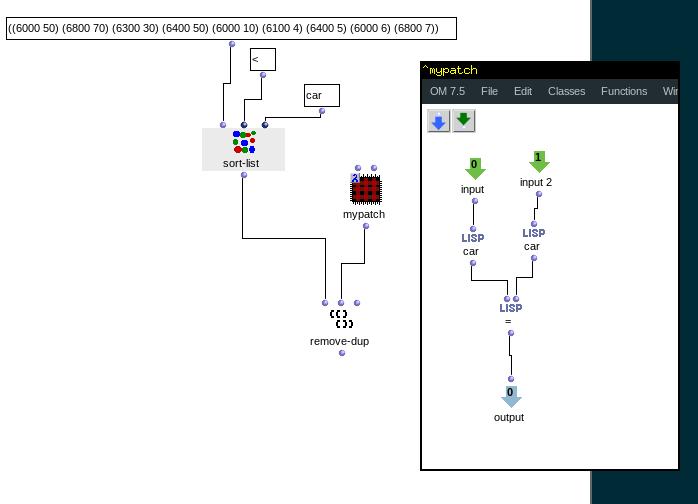
Je vais donc regarder de plus près les array dans Om, mais en somme ce que j’aimerais faire c’est appliquer toute sorte de fonctions test (tri, suppression…) sur les coordonnées des vecteur (note, dur, vel…) d’un chord-seq A, et rentrer les vecteurs résultants dans un chord-seq B.
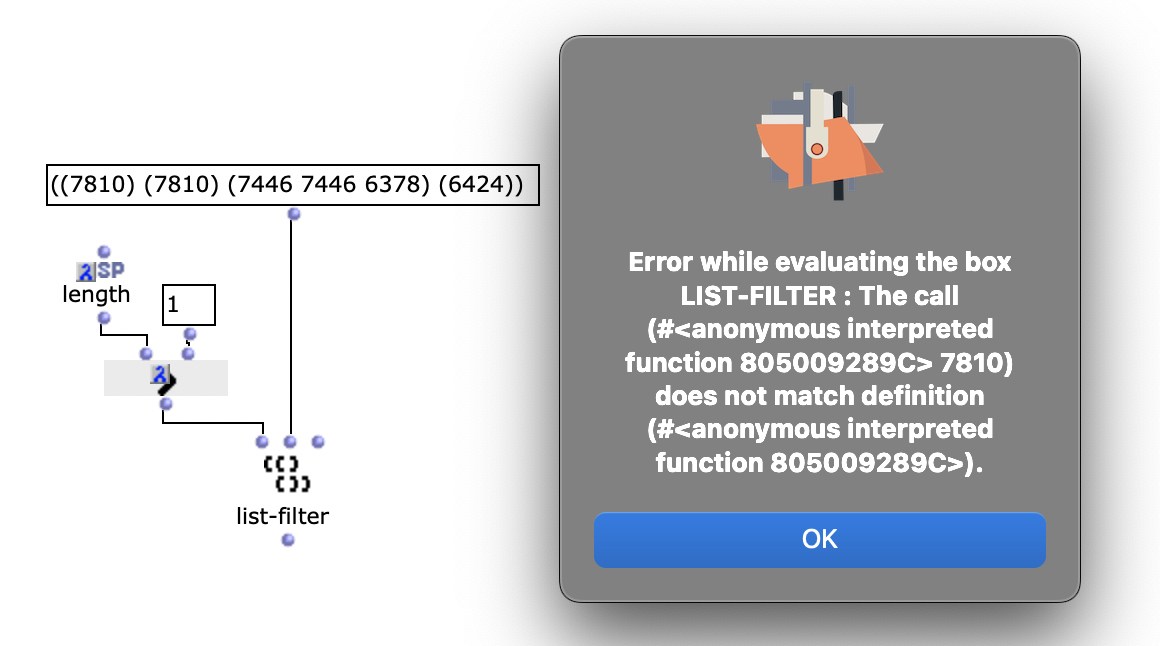
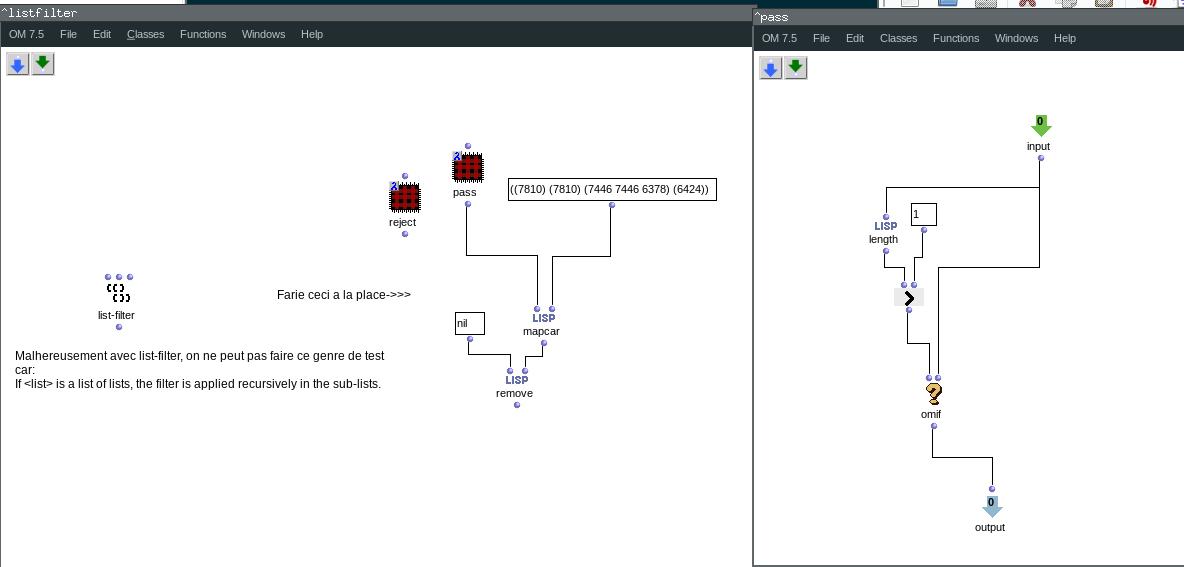
Un premier écueil rencontré est que parfois, dans lmidic, un vecteur comporte plusieurs notes pour un même onset. Il sera préférable d’avoir deux notes ‘individualisées’ : (6000) (6200) plutôt que (6000 6200), mais avec le même onset, afin de garantir la même longueur pour toutes les listes des coordonnées de vecteur : lmidic, lonset etc.
Bien à vous
Cyril